
ComfyUi na prática : Lora Training
A IA genérica joga dados; o engenheiro de imagem joga xadrez. Neste dossiê técnico, dissecamos o nó 'Train LoRA' do ComfyUI. Aprenda a curar datasets, ajustar o learning rate e criar modelos que obedecem à sua visão, não ao acaso. Workflow JSON incluso.


Do Caos à Identidade: Como Criar LoRAs Consistentes e Injetar Alma na sua IA.
A maioria dos usuários de Inteligência Artificial vive de sorte. Eles digitam um prompt, apertam um botão e rezam para que o algoritmo entenda o que está na cabeça deles. Isso não é criação; é loteria.
Se você está cansado da inconsistência e quer que a IA reproduza um estilo, um rosto ou um conceito específico com fidelidade absoluta, o prompt não é suficiente. Você precisa de um LoRA (Low-Rank Adaptation).
Neste tutorial, não vamos apenas “apertar botões”. Vamos dissecar o processo de criação de um LoRA utilizando o poder modular do ComfyUI. Vamos transformar a sua máquina em um ateliê de precisão.
O que você vai aprender hoje:
- A teoria por trás da “Injeção de Identidade” na IA.
- A preparação do dataset (onde 90% das pessoas erram).
- A configuração do nó de treinamento no ComfyUI.
- Como testar e refinar sua criação.
Prepare o café (ou o chá), abra o seu ComfyUI e vamos dominar esse caos.
Seção 1: O Que é um LoRA e Por Que Você Precisa Dele?
Imagine que o Stable Diffusion é uma enciclopédia gigante que sabe um pouco sobre tudo, mas não é especialista em nada. O LoRA não é um novo livro; é um post-it de alta complexidade que você cola em uma página específica.
Ele ensina ao modelo uma única coisa — seja o traço de um anime específico, a textura de um tecido ou o rosto de uma celebridade — sem a necessidade de retreinar o modelo inteiro (o que exigiria um supercomputador).
É a diferença entre pedir para um pintor “desenhar alguém parecido com fulano” e entregar uma foto 4×4 para ele copiar.
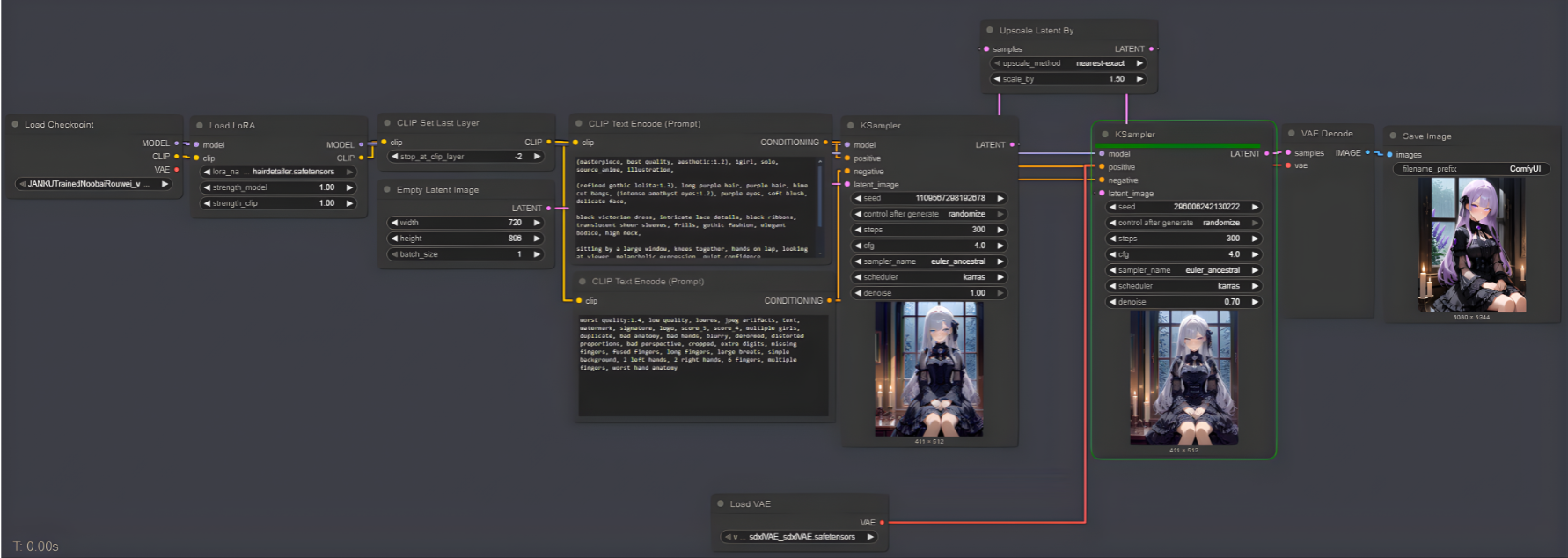
Seção 2: O Dataset – A Arte da Curadoria
Existe um ditado antigo na computação que é a lei absoluta do LoRA: “Garbage In, Garbage Out” (Lixo entra, lixo sai).
Não adianta ter a melhor placa de vídeo do mercado se o seu material de ensino for medíocre. Para criar um LoRA capaz de replicar a elegância da Charlotte (essa é minha personagem modelo mas serve para qualquer personagem complexo), você precisa agir não como um acumulador de arquivos, mas como um curador de museu.
As 3 Regras de Ouro do Dataset:
• Variedade de Ângulos: O modelo precisa entender a tridimensionalidade. Frente, perfil, meio-perfil. Se você só entregar fotos de frente, seu LoRA ficará “preso” nessa pose para sempre.
• Qualidade vence Quantidade: Esqueça os tutoriais que dizem para usar 100 imagens. Para um estilo ou personagem, 15 a 30 imagens de altíssima resolução e nitidez valem mais do que 500 imagens borradas ou comprimidas.
• Limpeza Visual: Se você quer que a IA aprenda o rosto e o vestido, evite fotos onde o fundo é uma poluição visual que compete com o sujeito. O foco deve ser claro.


O Segredo da Legendagem (Captioning)
A imagem é o corpo; o texto é a mente. Você precisa dizer à IA o que ela está vendo.
Se você não descrever o que não faz parte da essência do personagem (como “fundo de floresta” ou “cadeira”), a IA achará que a floresta faz parte da roupa dele.
- Dica Pro: Use legendas simples e diretas em arquivos
.txtcom o mesmo nome da imagem. - Exemplo para a Charlotte:
gothic lolita girl, purple hair, amethyst eyes, victorian black dress, sitting, indoors
Uma boa curadoria é 80% do trabalho. O treino é apenas a execução.
Seção 3: O Painel de Controle (Configurando o Nó “Train LoRA”)
Finalmente, chegamos ao momento da verdade. Este nó é onde você define as leis da física para o aprendizado da sua IA. Vamos descer item por item, explicando o que cada chave faz no seu motor.
Olhe para o seu nó Train LoRA e acompanhe comigo:
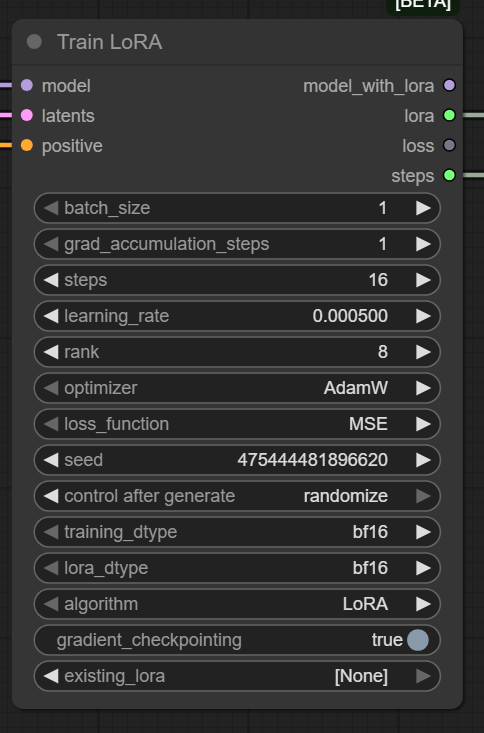
1. batch_size (O tamanho da mordida)
- O que é: Primeiramente, este valor define quantas imagens a sua placa de vídeo processa simultaneamente antes de fazer um ajuste matemático.
- Configuração: No print está 1.
- Recomendação: Se você tem pouca VRAM (8GB ou menos), deixe em 1. Se tiver uma RTX 3090 ou 4090, pode subir para 4 ou 6 para acelerar o processo. Atenção: Aumentar muito consome memória exponencialmente.
2. grad_accumulation_steps
- O que é: Um truque para simular um batch_size maior sem gastar memória.
- Recomendação: Mantenha em 1 para começar. Só mexa nisso se souber exatamente o que está fazendo com a estabilidade do gradiente.
3. steps (O tempo de forno)
- O que é: Em suma, isso determina quantas vezes a IA vai atualizar o “cérebro” dela.
- O Alerta: No entando, na imagem vemos 16. Cuidado: 16 passos é apenas um “piscar de olhos” para a IA, útil apenas para verificar se o sistema não vai travar.
- Para valer: Para um personagem complexo como a Charlotte, você precisará de centenas ou milhares de passos dependendo do tamanho do seu dataset.(ex: 1.000 a 2.000 steps, eu particularmente finalizo meus personagens com 50.000 mas isso vai ocupar sua maquina por varias horas, recomendo usar uma nuvem que irei ensinar em outro tutorial)
4. learning_rate (A velocidade de aprendizado)
- O que é: Basicamente, define quão agressivamente a IA muda o que sabe.
- Configuração: 0.000500.
- A Metáfora: Se for muito alto, a IA corre demais e tropeça (o LoRA fica caótico). Se for muito baixo, ela anda devagar demais e nunca aprende. O valor 0.0005 ou 0.0001 é o padrão ouro de segurança.
5. rank (A capacidade de armazenamento)
- O que é: Em outras palavras, é o tamanho do “cérebro” do LoRA. Define o quão complexo ele pode ser.
- Configuração: 8.
- Recomendação:
- 8 ou 16: Ótimo para estilos simples ou rostos. Gera arquivos leves (cerca de 10-20MB).
- 32, 64 ou 128: Necessário apenas se você estiver treinando conceitos extremamente complexos ou estilos artísticos inteiros. Arquivos ficam pesados (100MB+).
- 8 ou 16: Ótimo para estilos simples ou rostos. Gera arquivos leves (cerca de 10-20MB).
6. optimizer (O Professor)
- O que é: O algoritmo matemático que guia o aprendizado.
- Recomendação: AdamW. É o padrão da indústria. Não reinvente a roda aqui.
7. loss_function
- Configuração: MSE (Mean Squared Error). Deixe como está. É a régua que mede o quanto a IA errou para poder corrigir.
8. seed (A semente do caos)
- O que é: O número que inicia a aleatoriedade.
- Importante: Se você quiser repetir exatamente o mesmo treino no futuro para comparar mudanças, guarde este número.
9. training_dtype & lora_dtype (O formato dos dados)
- Configuração: bf16 (Brain Float 16).
- Por que usar: O formato
bf16é mais moderno e estável que o antigofp16, evitando que o treino “exploda” (gere erros numéricos) em placas da série RTX 3000 ou 4000. Se sua placa for antiga (GTX 1000), mude parafp16oufloat32.
10. gradient_checkpointing
• Essencial: Isso economiza MUITA memória de vídeo (VRAM) ao custo de um pouco de velocidade. Deixe sempre ligado se você não tiver uma placa de vídeo industrial.
• Configuração: true.
Seção 4: A Anatomia do Fluxo – Parte 1: O Cérebro e a Linguagem
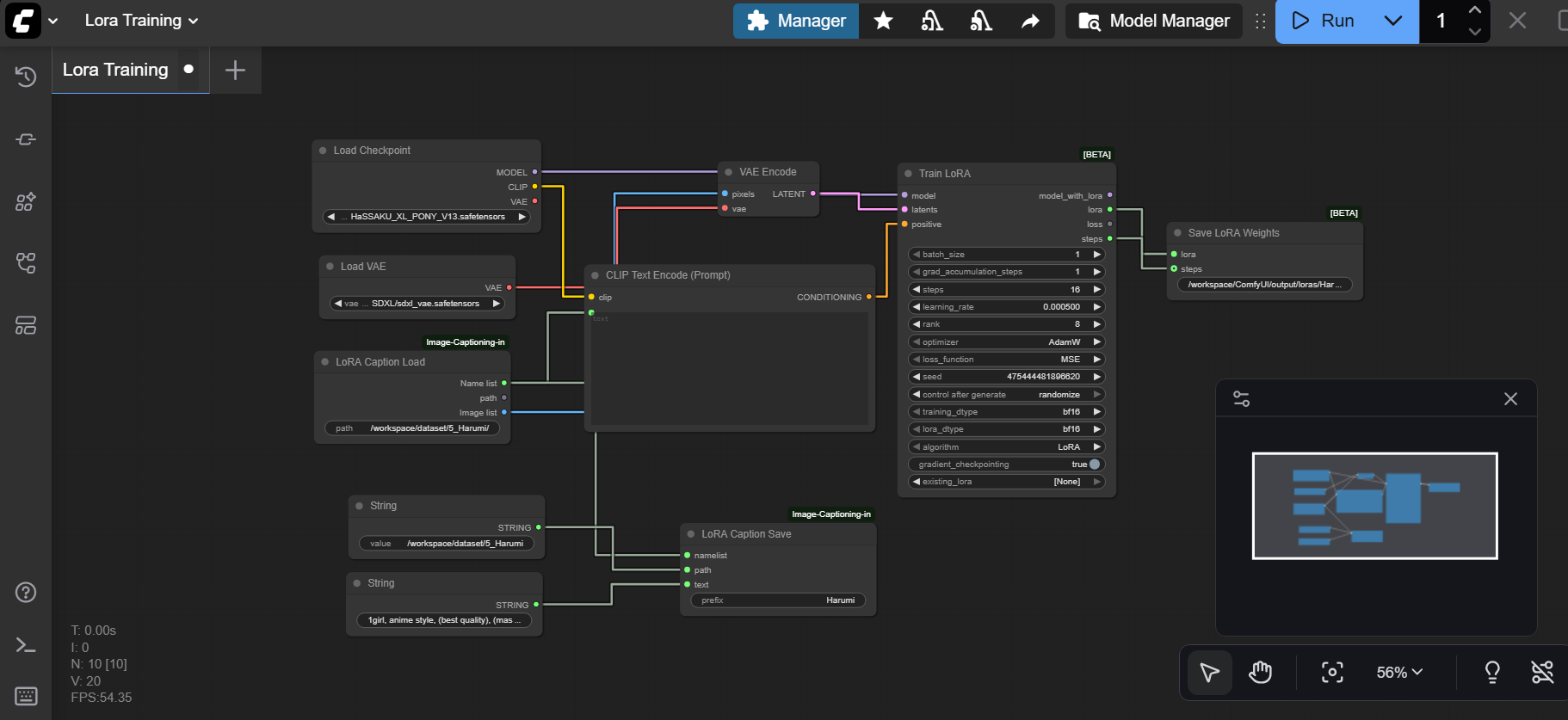
Então vamos começar pelo que define a inteligência e o vocabulário do seu treinamento.
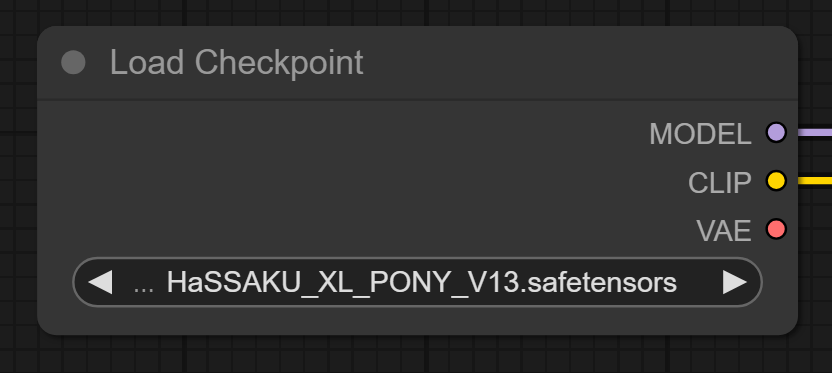
1. Load Checkpoint (A Base)
Tudo começa aqui. Inicialmente, este nó carrega o modelo principal que servirá de “professor”.
- No fluxo: Estamos usando o
HASSAKU_XL_PONY_V13.safetensors(mas recomendo usar o mesmo utilizado para fazer as imagens iniciais da sua personagem para o treino do lora). - A Conexão: Ele envia a saída
CLIPpara o próximo nó. Isso é essencial: o CLIP é a parte do cérebro da IA que entende palavras. Sem conectar isso, a IA vê imagens mas não sabe o nome delas.
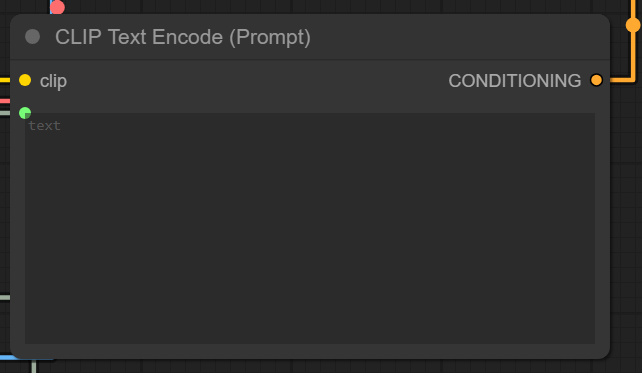
2. CLIP Text Encode (O Intérprete)
• Normalmente, você digitaria seu prompt aqui. Contudo, num treino de LoRA, este nó age de forma diferente. Ele recebe a “inteligência de texto” do Checkpoint e aguarda os dados brutos do seu Dataset.
- Atenção: Note que a caixa de texto está vazia. Isso é proposital. Ele vai receber as informações diretamente do nó de carregamento de dados (Caption Load).
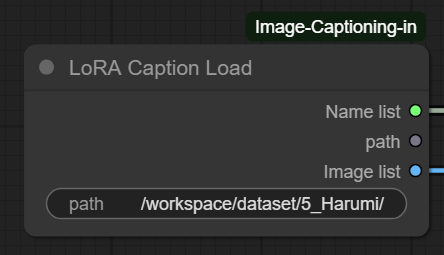
3. LoRA Caption Load (O Dataset e a Estrutura de Pastas)
Sem dúvida, aqui está o segredo que separa amadores de profissionais. Este nó diz ao ComfyUI onde estão suas imagens e textos.
- O Caminho (Path): No exemplo, vemos
/workspace/dataset/5_Harumi/. - A Regra da Pasta (“Repeats”): Perceba o número 5 no início do nome da pasta (
5_Harumi). Isso não é estético.- Isso é um comando matemático. Diz ao treinador: “Repita cada imagem desta pasta 5 vezes por época”.
- Matemática: Se você tem 20 imagens nessa pasta, a IA processará 100 imagens por época (20 x 5). Isso é vital para equilibrar o quanto a IA aprende.
- Conteúdo da Pasta: Dentro dela, devem estar pares perfeitos:
imagem01.png+imagem01.txt.
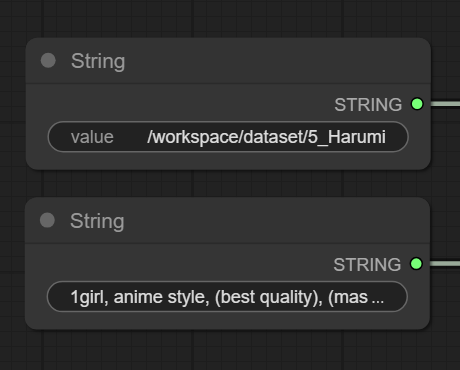
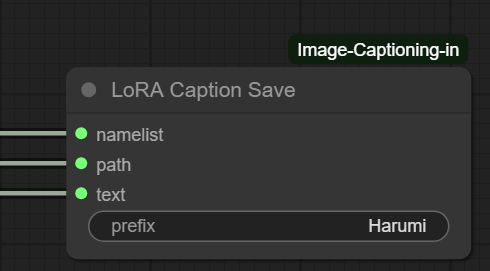
4. LoRA Caption Save & Strings (O Refinamento)
Muitos ignoram esta parte, mas nós não. Aqui nós processamos e salvamos como a IA está lendo nossas legendas.
- Nós “String”: Você vê dois nós amarelos de texto alimentando este bloco.
- String 1 (Caminho): Onde salvar os dados processados. (pasta onde armazenou suas imagens e blocos de texto)
- String 2 (Prefix/Trigger Word): Vemos o texto
1girl, anime style.... Aqui você pode forçar uma “palavra-gatilho” (Trigger Word) para que todas as suas imagens sejam associadas a ela (ex:Charlotte). - LoRA Caption Save: Ele pega os dados brutos do Load, aplica o prefixo do String e salva uma versão otimizada para o treino.
Seção 4: A Anatomia do Fluxo – Parte 2: A Visão e o Treino
Agora que a IA já sabe “ler” e tem os dados, precisamos ensinar ela a “ver”.
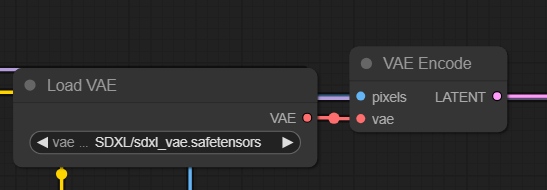
5. Load VAE & VAE Encode (A Visão)
Lembre-se que a IA não enxerga pixels (JPG/PNG); ela enxerga matemática (Latents).
- Load VAE: Carregamos o
sdxl_vae.safetensors. Usar um VAE específico (e não o genérico do checkpoint) garante cores mais vivas e detalhes nítidos. - VAE Encode: Este nó pega as imagens (pixels) vindas do LoRA Caption Load e usa o VAE para traduzi-las para o espaço latente (
LATENT). É esse código que entra na máquina de treino.
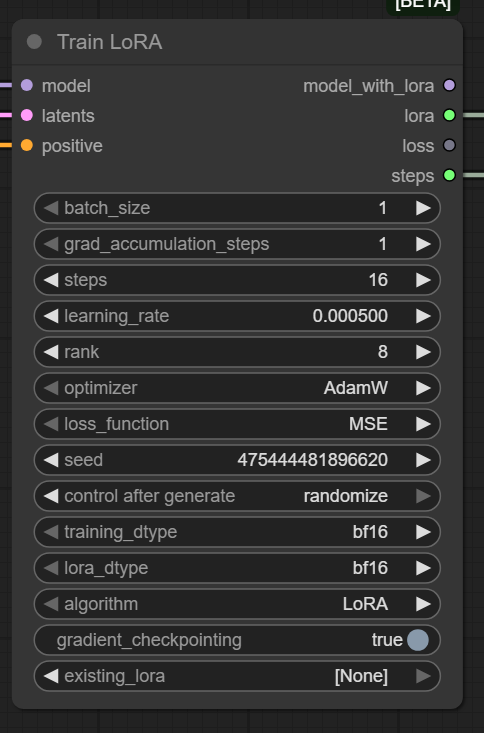
6. Train LoRA (O Coração da Operação)
Finalmente, aqui todos os rios se encontram.
- Entradas:
-
model: Vem do Checkpoint.-
positive: Vem do CLIP Text Encode (o conceito).-
latents: Vem do VAE Encode (a imagem traduzida).
-
-
-
- É aqui que aplicamos as configurações de learning_rate e steps que detalhamos na seção anterior. Ele pega o modelo, olha a imagem (latents), lê a legenda (positive) e calcula como ajustar o modelo para criar aquilo.
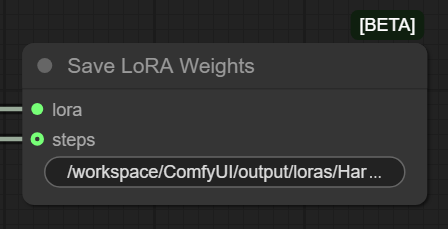
7. Save LoRA Weights (O Nascimento)
Por fim, chegamos ao passo final.
• Conexão: Ligado diretamente à saída lora do nó de treino. Sem isso, todo o seu esforço se perde na memória RAM quando você fecha o programa.
• Função: Ele pega o resultado matemático do nó Train LoRA e o solidifica em um arquivo .safetensors que você poderá usar.
Conclusão: O Caos Sob Controle
Se você seguiu este guia até aqui, você não tem mais “sorte” na geração de imagens. Você tem método.
Treinar um LoRA não é sobre queimar placas de vídeo; é sobre capturar uma essência. Seja para preservar um estilo artístico, replicar um personagem consistente (como a nossa querida Charlie) ou inserir sua marca no universo da IA, a técnica que você aprendeu hoje é o que separa os curiosos dos profissionais.
Mas eu prometi que a DLV AI não entregaria apenas teoria. Nós entregamos ferramentas.
Para garantir que você não perca horas ligando fios virtuais, nós preparamos o Workflow Mestre usado neste tutorial. Ele já vem configurado com a estrutura de pastas, os nós de legenda e as configurações de treino otimizadas que discutimos.
📥DOWNLOAD: Workflow Completo Luminose City Lora Training.JSON (Clique para baixar e arraste para dentro do seu ComfyUI)
🔮O Próximo Passo: A “Escriba” (Automatizando o Chato)
Você deve ter notado que deixamos uma peça do quebra-cabeça propositalmente de fora: A criação dos arquivos de texto (Captioning).
Sabemos que descrever 50 imagens manualmente é o trabalho mais ingrato da Terra. Por isso, decidimos que ele não merece apenas um parágrafo, mas uma solução definitiva.
No próximo post, vamos liberar gratuitamente a “Escriba”: nossa ferramenta exclusiva que analisa suas imagens e cria os arquivos de texto automaticamente, com a precisão de um especialista.
Esqueça o trabalho braçal. Nós resolvemos isso para você.
Marque a gente em suas redes sociais e compartilhe nossos tutoriais para auxiliar a comunidade
@Luminose.City
@Regia_LCN
Boa sorte e bom treino.
— Regia LCN & Charlotte🥀
Inscreva-se na newsletter / Fique atento ao blog.


